Understanding OSPF and its Concepts
OSPF is a link-state protocol and there are two major steps in the link state protocols.
• The routers a lot of information regarding the network such as routers, links, IP addresses, status information and so on.
• Then the routers flood all this information so that each router in the network knows all the information. once the information is flooded, each router finds the shortest path respective to its own path.
OSPF organizes the information and builds the topology on basis of LSA(Link State Advertisements) which are collected in a database known as LSDB(Link State Data Base).
LSA is a data structure with specific information about the database.

The above figure shows the basic flooding of LSA’s for router 8. The router 8 doesn’t send LSA to each router. what it does it asks the router if it has a copy of LSA and if not then sends the LSA. The router sends this information for every minute change in LSA information so that each router has exact same information.\
Just by sharing the LSA and LSDB information through all the router is not sufficient to determine the ip routes. we have to calculate the ip routes on basis of the common LSDB in routers. In order to do that routers use an algorithm known as Djikstra Shortest Path First(SPF) algorithm. It calculates the routes on basis of LSDB.
There are three main phases of OSPF in which the routers exchange the LSA’s and calculate the IP routes.
• Becoming neighbors
• Exchanging Databases
• Adding the best routes
OSPF neighbors Concept:
• Two routers can become OSPF neighbors if they are connected to the same vlan or connected to same serial link or connected via same WAN link.
• Other than connecting to the same link, the routers need to send messages and agree to them to become ospf neighbors. for this OSPF sends hello message to its neighbors to see if they have compatible ospf settings.
• We can view the above information by using show ip ospf neighbors
• when one of the routers fails i.e., it is unable to respond to ospf hello messages then it re floods LSA to all other routers to find the best possible route. That is why convergence works fast in OSPF.
• We initially said that routers use hello messages to establish its neighbors, by hello messages it lists the router ID(RID) OSPF RID are 32-bit numbers, as a result most command outputs these as dotted-decimal-notation(DDN).
- The OSPF neighbors shares the hello messages as shown below in the figure, The router sends hello to multicast address through its ports and expects to find a return hello message.

• The Hello message has following features.
■ The Hello message follows the IP packet header, with IP protocol type 89.
■ Hello packets are sent to multicast IP address 224.0.0.5, a multicast IP address intended for all OSPF speaking routers.
■ OSPF routers listen for packets sent to IP multicast address 224.0.0.5, in part hoping to receive Hello packets and learn about new neighbors.
- Observer the figure below, it shows how the router gain and maintain communication as ospf neighbor.

• The two-way state is very important state and the following conjectures are true at that state.
■ The router received a Hello from the neighbor, with that router’s own RID listed as being seen by the neighbor.
■ The router has checked all the parameters in the Hello received from the neighbor, with no problems. The router is willing to become an OSPF neighbor.
■ If both routers reach a 2-way state with each other, it means that both routers meet all OSPF configuration requirements to become neighbors. Effectively, at that point, they are neighbors and ready to exchange their LSDB with each other.
Exchanging LSDB between neighbors:
As we discussed above once the two routers are in two-way state then they are ready to exchange LSDB with each other. Before sending LSDB they first share the list of LSA with each other they use it as a checklist to check whether they have received all the LSA or not.
The OSPF messages that sends LSA’s are called Link State Updates(LSU). The packet LSU contains LSA as data structures.
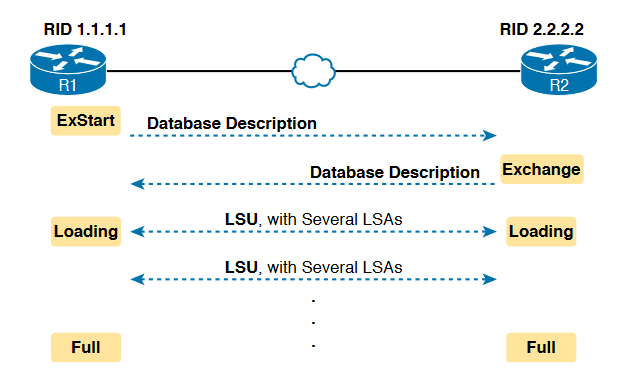
From the above figure we can observe two points clearly, they are:
■ The routers exchange the LSAs inside LSU packets.
■ When finished, the routers reach a full state, meaning they have fully exchanged the contents of their LSDBs.
In order to maintain constant relationship as neighbors, they constantly send hello messages at a certain time interval and that time interval is called Hello Interval.
If the neighbor doesn’t responds to the hello messages even after certain time interval (usually four times that of hello interval) then that means the neighbor is failed, and that certain time interval is known as Dead Interval
To summarize the task that happen during maintenance of neighbors are as follows:
■ Maintain neighbor state by sending Hello messages based on the Hello Interval and listening for Hellos before the Dead Interval expires
■ Flood any changed LSAs to each neighbor
■ Reflood unchanged LSAs as their lifetime expires (default 30 minutes)
Concept of Designated Routers:
We have earlier discussed that the routers share LSDB with each other. But it doesn’t happen the way like they share in between them in same vlan or subnet.
Instead they chose a router namely Designated Router. which will act as a focal point in sending and receiving all the LSDB’s in the same vlan or subnet.
Incase if Designated router fails we should have another router as DR and that router in known as Backup Designated Router(BDR)

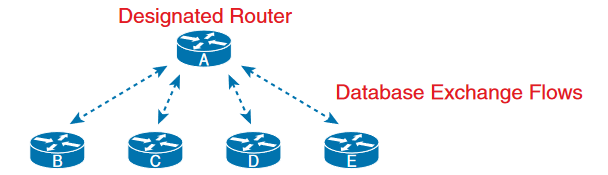
From the above two figures we can observe how the routers change the LSDB with use of DR and BDR.
The routers which aren’t neither DR nor BDR are known as DROthers. Some of these routers will remain in two way state under normal operating conditions. From the above figure we can conclude as following.
■ Two neighbors (A and B, the DR and BDR, respectively) with a full state (called fully adjacent neighbors)
■ Two neighbors (D and E, which are DROthers) with a 2-way state (called neighbors)

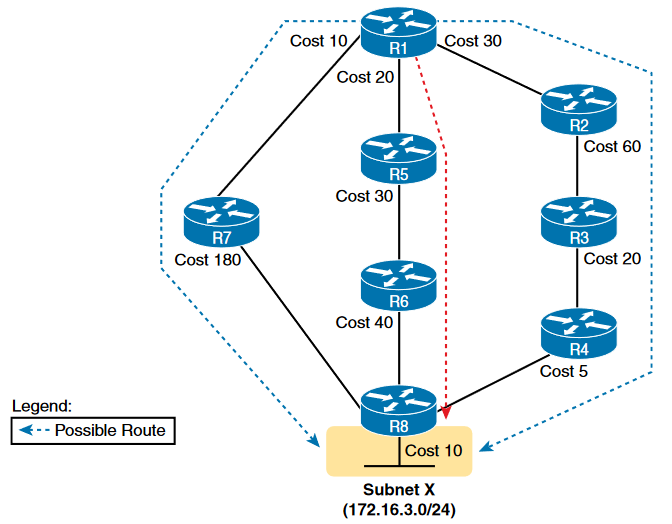
Calculating Best Routes with SPF:
After the routers collect the LSDB’s they are calculated accordingly with SPF algorithm and then they add the following to the routing table.
1. A route with subnet number and mask
2. An outgoing interface
3. Next-hop router IP address

OSPF Areas and LSA’s:
If there are large number of routers operating on OSPF then it takes a lot of time for convergence. The routers might run on low amount of RAM as well. Additional problems occur as follows if we use a single area.
■ A larger topology database requires more memory on each router.
■ The SPF algorithm requires processing power that grows exponentially compared to the size of the topology database.
■ A single interface status change anywhere in the inter network (up to down, or down to up) forces every router to run SPF again!
The solution for this is to divide the LSDB into different small areas, by doing this we can reduce the load on CPU and RAM and also we don’t have to run OSPF on every router in the network using OSPF. The limit for no.of routers in a single area are limited to 50.
Concept of OSPF Areas:
The areas are designated by following the rules as listed below.
■ Put all interfaces connected to the same subnet inside the same area.
■ An area should be contiguous.
■ Some routers may be internal to an area, with all interfaces assigned to that single area.
■ Some routers may be Area Border Routers (ABR) because some interfaces connect to the backbone area, and some connect to non backbone areas.
■ All non backbone areas must have a path to reach the backbone area (area 0) by having at least one ABR connected to both the backbone area and the non backbone area.
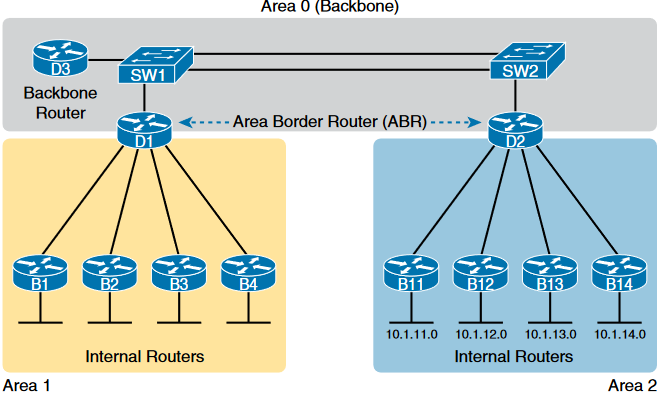

The above figure shows some definitions and distinctions regarding the OSPF areas.
Impact of concept of areas on SPF Calculation Time:
The main benefit of dividing the network in to areas is we reduce the topology of the network. So SPF has to exert less time and cpu power to calculate routes within that area. Other than that there are more advantages of using areas which are listed below.
■ Routers require fewer CPU cycles to process the smaller per-area LSDB with the SPF algorithm, reducing CPU overhead and improving convergence time.
■ The smaller per-area LSDB requires less memory.
■ Changes in the network (for example, links failing and recovering) require SPF calculations only on routers in the area where the link changed state, reducing the number of routers that must rerun SPF.
■ Less information must be advertised between areas, reducing the bandwidth required to send LSAs.
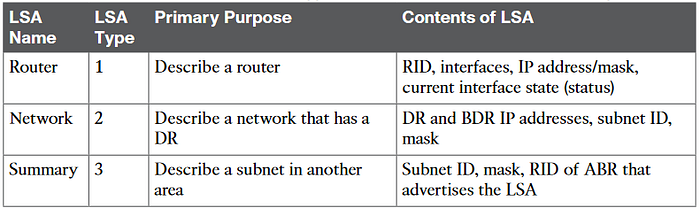
OSPF(v2) Link State Advertisements:
OSPF defines the first two types of LSAs to define those exact details, as follows:
■ One router LSA for each router in the area
■ One network LSA for each network that has a DR plus one neighbor of the DR
The ABR creates summary information about each subnet in one area to advertise into other areas
■ One summary LSA for each subnet ID that exists in a different area
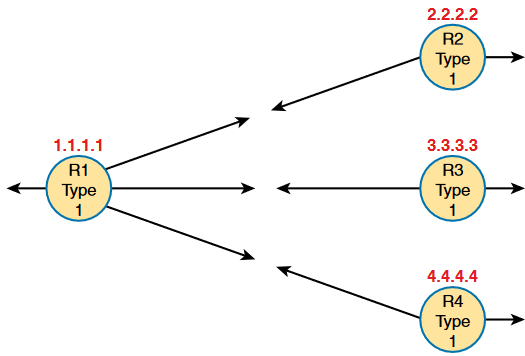
Router LSAs, also known as Type 1 LSAs, describe the router in detail. Each lists a router’s RID, its interfaces, its IPv4 addresses and masks, its interface state, and notes about what neighbors the router knows about via each of its interfaces.
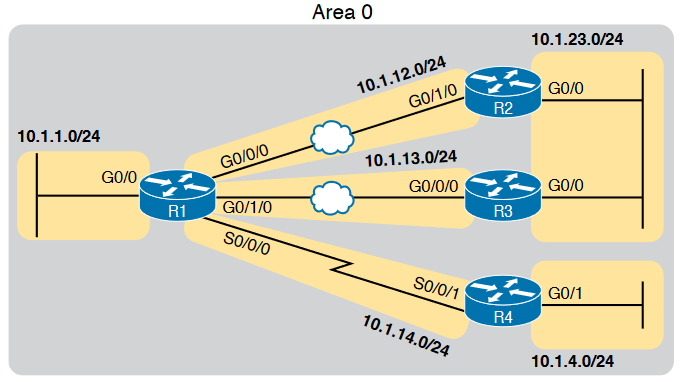
The model for the above network topology can be viewed as follows.
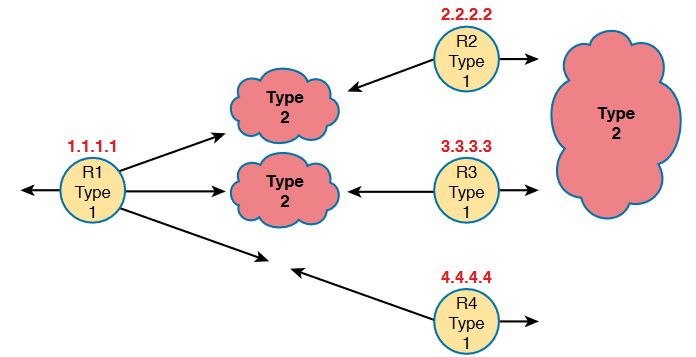
Now let us assume that there is a LAN connection between R2 and R3 and also two WAN connections between R1 and R2, R1 and R3. From that we can say that.The Ethernet LAN between R2 and R3 will elect a DR, and the two routers will become neighbors; so, whichever router is the DR will create a network LSA. Similarly, R1 and R2 connect with an Ethernet WAN, so the DR on that link will create a network LSA. Likewise, the DR on the Ethernet WAN link between R1 and R3 will also create a network LSA.
Reference :
https://www.amazon.in/CCNA-200-301-Official-Cert-Guide/dp/0135792738